Integrations detection pipeline
This page tells you how Sophos product integrations ingest, filter, clean, correlate, and escalate detections.
Note
To find out how to monitor the number of detections being collected and processed, see Telemetry journey.
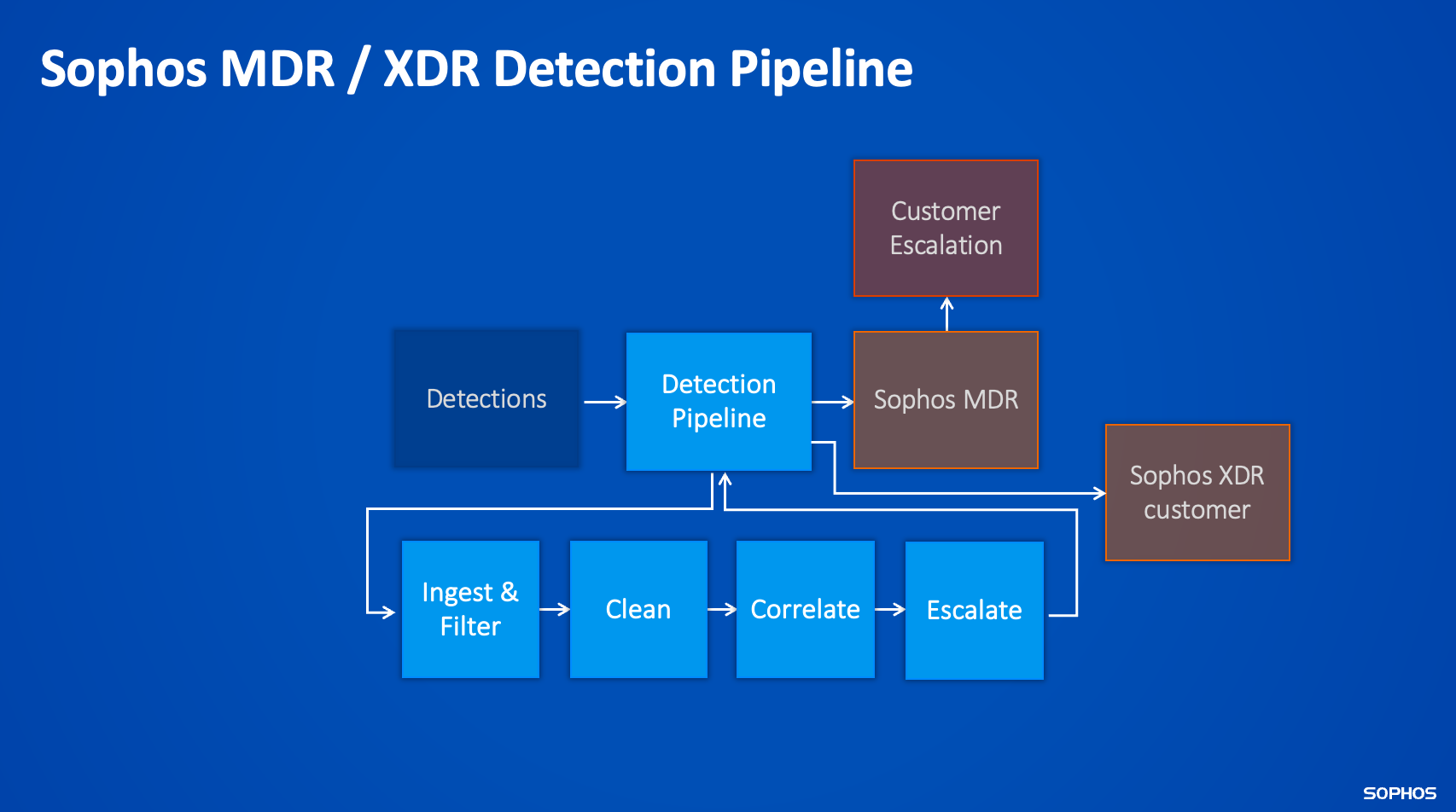
Step 1: Ingest and filter
We ingest the telemetry and filter out the unwanted noise.
We do this in one of the following ways:
- On-premises: A log collector on the customer network forwards alerts to Sophos Central.
- In the cloud: An API sends alerts to Sophos Central.
Note
To protect continuity of service for all users, Sophos sometimes filters or samples customers' data input. This shows up as temporary differences between alert volume at ingest and processing stages. It can also lead to re-queueing of data so it can be reprocessed to give the customer comprehensive coverage.
Step 2: Clean
The data we ingest isn't standardized, so Sophos begins to process it into a consistent and normalized schema.
Step 3: Correlate
We now begin grouping the seemingly unrelated raw alerts into related alert clusters.
We use the following criteria for grouping alerts:
- We aim to have each alert cluster representing a related activity.
- We group alerts through time, based on the MITRE ATT&CK technique and similar Indicators of Compromise (IOCs) or entities.
- We use the MITRE framework to help us group events based on specific threat use-cases.
Step 4: Escalate
The logic now decides which clusters to escalate to our analysts for further investigation.
If necessary, the analyst will investigate, and we'll notify the customer about the investigation.
We usually provide the following information:
- A description of the incident.
- Specific alert details that seem to indicate the most severe threat.
- Any specific infrastructure that's under threat.
- Any specific times that events occurred.
- Verdict on how severe the threat is (whether it's a serious issue or a false positive, whether all alerts are actioned).
- Any mitigation steps.